
The increasingly mature artificial intelligence technologies, such as big data, deep learning, and natural language processing, provide technical support for research on automatic text understanding and bring development opportunities for innovative measurement of scientific communication. Innovation detection and analysis is a challenging and cutting-edge direction in Informatics. It is interdisciplinary, requiring considering the characteristics of different disciplines and different types of scientific outcomes to establish a comprehensive evaluation metrics system. On the other hand, metadata and content features should be considered to reflect the innovation of scientific works objectively and comprehensively. This project aims to identify the main factors of science and developing predictive models to capture its evolution to provide a broader perspective on measuring and analyzing the innovative nature of science. Advanced AI techniques, such as knowledge reasoning, large-scale pre-trained language models will be explored for potential solutions.
Wang, Z., Zhang, H., Chen, J., & Chen, H. (2024). An effective framework for measuring the novelty of scientific articles through integrated topic modeling and cloud model. Journal of Informetrics, 18(14), 101587.
Wang, Z., Zhang, H., Chen, H., Feng, Y., & Ding, J. (2024). Content-based quality evaluation of scientific papers using coarse feature and knowledge entity network. Journal of King Saud University Computer and Information Sciences, 36(6), 102119.
Wang, Z., Qiao, X., Chen, J., Li, L., Zhang, H., Ding, J., & Chen, H. (2024). Exploring and evaluating the index for interdisciplinary breakthrough innovation detection. The Electronic Library, Vol. 42 No. 4, pp. 536-552.
Wang, Z., Peng, S., Chen, J., Zhang, X., & Chen, H. (2023). ICAD-MI: Interdisciplinary concept association discovery from the perspective of metaphor interpretation. Knowledge-Based Systems, 110695.
Wang, Z., Peng, S., Chen, J., Kapasule, A. G., & Chen, H. (2023). Detecting interdisciplinary semantic drift for knowledge organization based on normal cloud model. Journal of King Saud University-Computer and Information Sciences, 35(6), 101569.
Wang, Z., Chen, J., Chen, J., & Chen, H. (2023). Identifying interdisciplinary topics and their evolution based on BERTopic. Scientometrics, 1-26.
Wang, Z., Wang, K., Liu, J., Huang, J., & Chen, H. (2022). Measuring the innovation of method knowledge elements in scientific literature. Scientometrics, 127(5), 2803-2827.
Chen, H., Nguyen, H., & Alghamdi, A. (2022). Constructing a high-quality dataset for automated creation of summaries of fundamental contributions of research articles. Scientometrics, 127(12), 7061-7075.
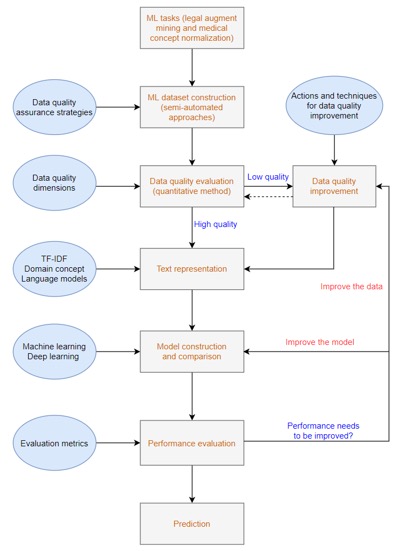
Machine learning (ML) has drawn great attention from academics as well as industries during the past decades and continues to achieve impressive human-level performance on nontrivial tasks such as image classification, voice recognition, natural language processing, and autopiloting. Both data and algorithms are critical to ensure the performance, fairness, robustness, reliability, and scalability of ML systems. However, artificial intelligence (AI) researchers and practitioners overwhelmingly concentrate on algorithms while undervaluing the impact of data quality. Due to the limitations of algorithmic solutions in AI success, scholars have proposed data-centric AI, with the initiative to carefully design the datasets, evaluate and improve the data quality for enhancing ML systems. This project focuses on data quality in ML, particular on how to use state-of-the-art technology on assessment, assurance, and improvement of big data for building high-quality ML systems.
Nguyen, H., Chen, H., Chen, J., Kargozari, K., & Ding, J. (2023). Construction and evaluation of a domain-specific knowledge graph for knowledge discovery. Information Discovery and Delivery.
Tran, N., Chen, H., Bhuyan, J., & Ding, J. (2022). Data Curation and Quality Evaluation for Machine Learning-Based Cyber Intrusion Detection. IEEE Access, 10, 121900-121923.
Chen, H., Chen, J., & Ding, J. (2021). Data evaluation and enhancement for quality improvement of machine learning. IEEE Transactions on Reliability, 70(2), 831-847.
Tran, N., Chen, H., Jiang, J., Bhuyan, J., & Ding, J. (2021). Effect of Class Imbalance on the Performance of Machine Learning-based Network Intrusion Detection. International Journal of Performability Engineering, 17(9).
Tang, M., Su, C., Chen, H., Qu, J., & Ding, J. (2020, December). SALKG: a semantic annotation system for building a high-quality legal knowledge graph. In 2020 IEEE International Conference on Big Data (Big Data) (pp. 2153-2159). IEEE.
Chen, H., Cao, G., Chen, J., & Ding, J. (2019). A practical framework for evaluating the quality of knowledge graph. In Knowledge Graph and Semantic Computing: Knowledge Computing and Language Understanding: 4th China Conference, CCKS 2019, Hangzhou, China, August 24–27, 2019, Revised Selected Papers 4 (pp. 111-122). Springer Singapore.
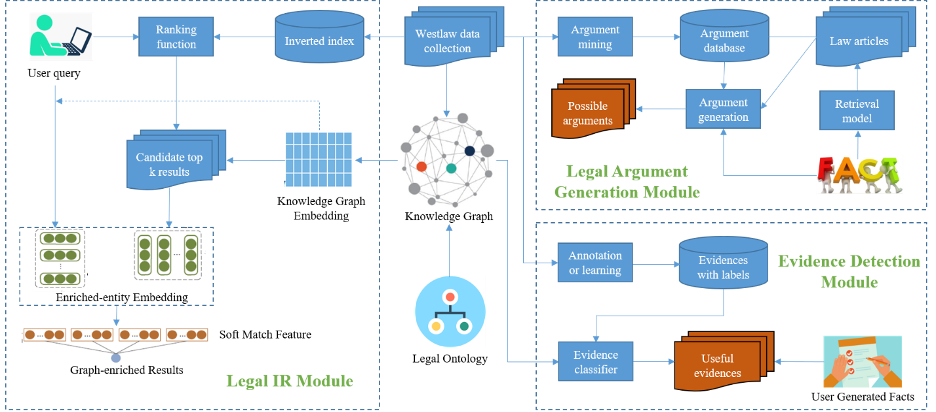
In the last decades, traditional information sources have largely been replaced by their digital counterparts, legal information users (ordinary people, legal librarians and researchers, lawyers, or judges) thus rely on digital information sources as assistance to solve legal problems. Making efficient use of these digital resources requires advanced techniques, such as information retrieval (IR), evidence building, and argument generation emerge. Legal IR aims to find proper legal information quickly and accurately, usually acts as the foundation of evidence building and argument generation, legal evidence building is to find a set of facts that can be inference for a claim, argument generation focuses on generating complete arguments out of facts. Legal evidence building and argument generation are two innovative but useful tasks which have been rarely touched by researcher because of the immensity and complexity of legal information. Therefore, this project will explore newly developed techniques in natural language processing and deep learning to build efficient and robust IR, evidence, and argument generation systems in legal domain, which will benefit legal information users for better decision making.
Chen, H., Wu, L., Chen, J., Lu, W., & Ding, J. (2022). A comparative study of automated legal text classification using random forests and deep learning. Information Processing & Management, 59(2), 102798.
Chen, H., Pieptea, L. F., & Ding, J. (2022). Construction and evaluation of a high-quality corpus for legal intelligence using semiautomated approaches. IEEE Transactions on Reliability, 71(2), 657-673.
Tang, M., Su, C., Chen, H., Qu, J., & Ding, J. (2020, December). SALKG: a semantic annotation system for building a high-quality legal knowledge graph. In 2020 IEEE International Conference on Big Data (Big Data) (pp. 2153-2159). IEEE.
With the advancement of AI-powered language models, such as ChatGPT, generative AI (AIGC, a.k.a AI-generated content) are being discussed and used in every aspect of human society. Generative AI has strong ability to analyze and create text, images, code, and beyond. In addition to the fundamental techniques behind AIGC and the popular tasks of AIGC, it is also being widely applied to different fields and domains, including question answering, marketing, healthcare, gaming, music, drug discovery, etc. Researchers and scientists have also started discussing the general design principles for generative AI applications. However, it is undeniable that the generative AI revolution is still in the early stage, and it can change and improve with the potential for even greater future capability. This project aims to investigate: (1) Frameworks and methodologies of evaluating the capacity and limitations of Generative AI in specific domains. (2) The applications of Generative AI in high stake domains, such as legal, medical, cyber security, and others. (3) Generative AI for information extraction, information retrieval, questions answering, text summarization, and other similar tasks. (4) Data argumentation with Generative AI. (5) Quality assurance for Generative AI. (6) Methodologies of quality evaluation of AI generated content. (7) Generative AI for future teaching and learning.
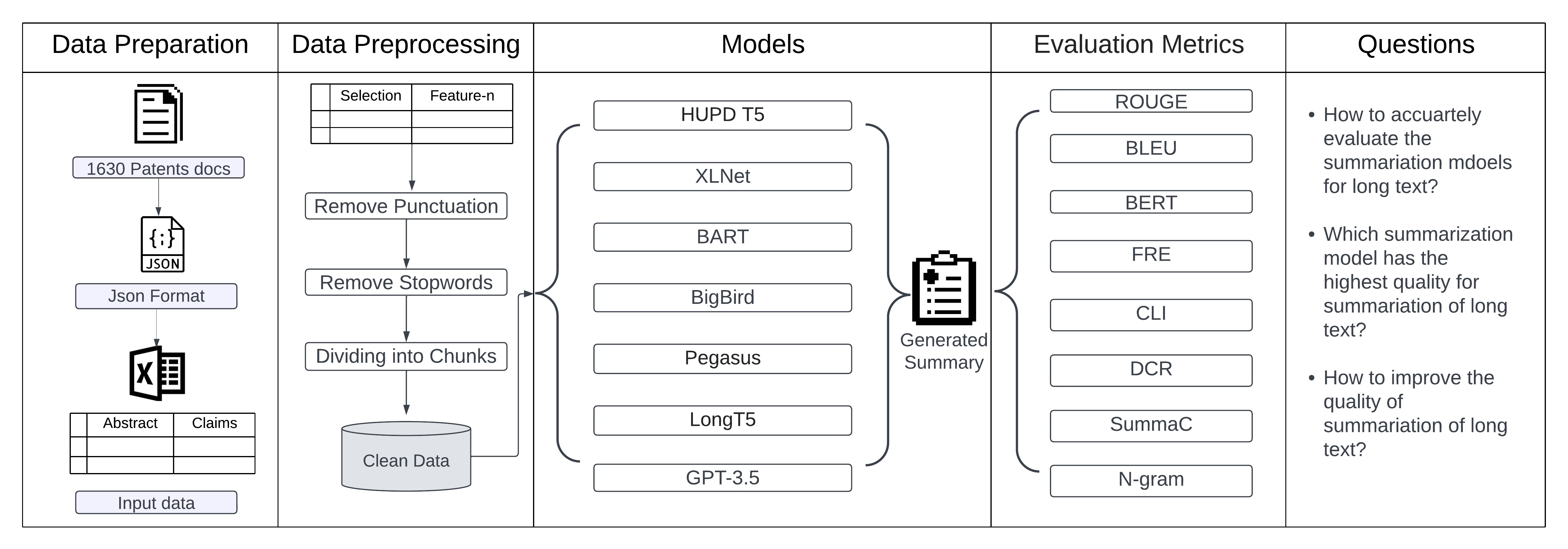
Ding, J., Chen, H., Kolapudi, S., Pobbathi, L., & Nguyen, H. (2023, October). Quality Evaluation of Summarization Models for Patent Documents. In 2023 IEEE 23rd International Conference on Software Quality, Reliability, and Security (QRS) (pp. 250-259). IEEE.
Nguyen, H., Chen, H., Maganti, R., Hossain, K. T., & Ding, J. (2023, July). Measurement and Identification of Informative Reviews for Automated Summarization. In 2023 IEEE International Conference on Artificial Intelligence Testing (AITest) (pp. 146-151). IEEE.
Zhao, H., Chen, H., & Yoon, H. J. (2023, July). Enhancing Text Classification Models with Generative AI-aided Data Augmentation. In 2023 IEEE International Conference on Artificial Intelligence Testing (AITest) (pp. 138-145). IEEE.
